• Invited Blog Post • WS-DL Blog
Hypercane Part 3: Building Your Own Algorithms
By Shawn M. Jones
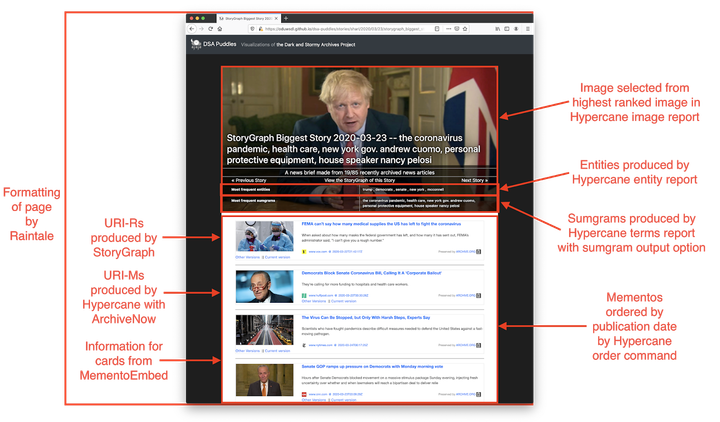
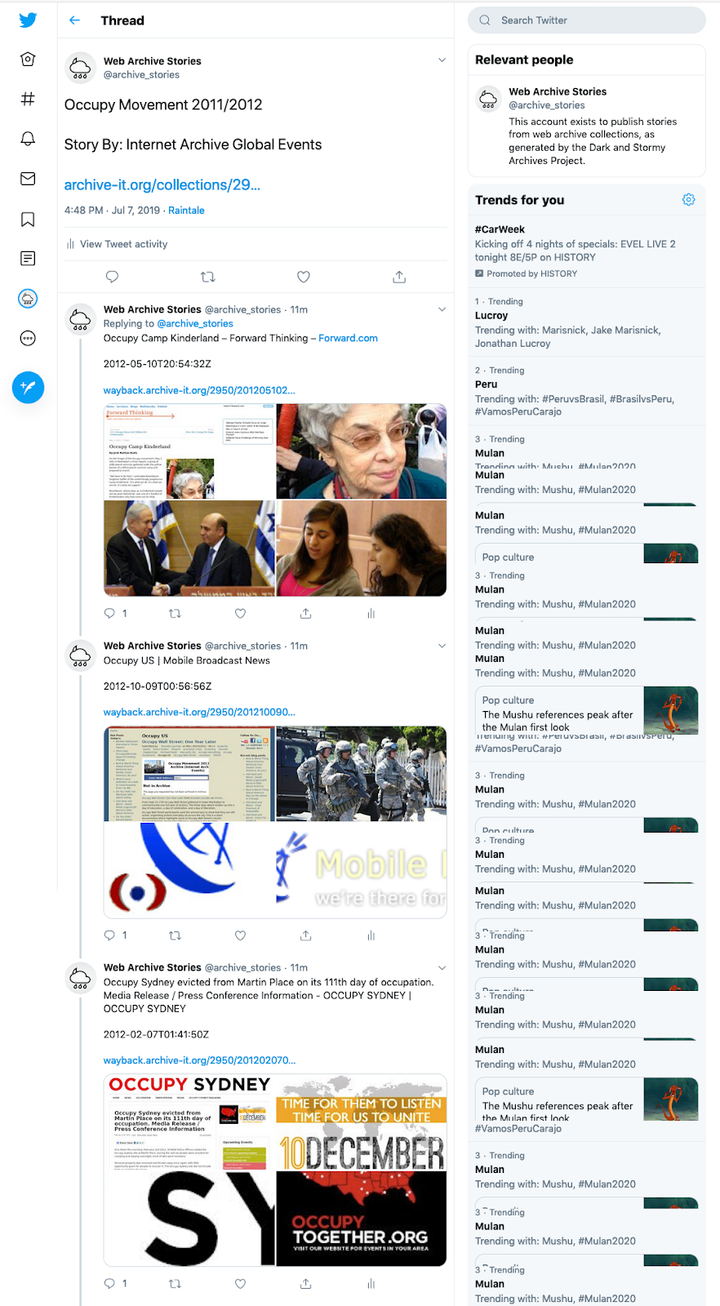
In Part 1, we introduced Hypercane, a tool for automatically sampling mementos from web archive collections. Web archive collections consist of thousand...